


In my last post, you read about SIP call recovery from RTP loss. This post continues the theme, providing some more useful information – detecting and dealing with RTP loss between two SIP end points.
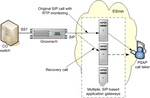
If you recall the scenario, there is a gateway installed between an SS7 carrier network and an emergency services IP network – an ESInet – over which emergency calls are routed to public safety answering points (PSAPs). Calls entering the ESInet via the gateway are SIP/RTP/UDP and, as the NENA i3 specification quite rightly states, in no circumstances should an in-progress emergency call be taken down automatically, just because RTP streams fail.
Whatever effort you put into making the call handling equipment redundant and resilient, it is always best to assume that bad things can still happen. To misappropriate the principle of simplicity from Ockham’s razor, follow the rule of thumb that advises, “Make as few assumptions as possible.” In fact, make one assumption only – expect the worst (i.e., ‘the proverbial’ happens).
So, we can expect situations to arise in which RTP media between the gateway and the ESInet fails.
PSAP equipment must be able to distinguish between RTP failure and real silence by a caller. That capability must apply at all points on an ESInet where RTP media is encountered by a device – from the gateway right through to the PSAP. The gateway uses technology – some form of digital signal processing, using either hardware (DSPs) or software (HMP) – to encode the media, and that same functionality will be used to detect the presence of RTP streams and distinguish between packets of silence or ‘speech’.
So far, so good, but as suggested, in a prediction far more likely than a prophecy from a Nostradamus quatrain to come true, the worst will happen and an RTP stream will fail.
Using SIP OPTIONS here is not entirely adequate – yes, that’s a good method of monitoring the far end, but only in so far as it confirms the presence of a signalling capability at the User Agent. A 200OK response doesn’t confirm the presence of RTP; merely that the signalling link is functioning. So, for what are we catering?
It’s not a failure of the gateway with which we need to deal – it’s a failure from (or towards) the other end. It might be counterintuitive, but when the device at the far end fails, it doesn’t know it’s failed, because it can’t tell if the gateway has received any RTP. Furthermore, although the gateway can tell if it’s receiving RTP, it can’t tell if the other device is receiving its RTP. The point being, half the solution has to be implemented at each end in order to achieve a whole result. That is, similar signal processing functionality needs to be implemented at both ends.
If there’s been a failure in transmitting RTP from the remote end equipment, the gateway clearly isn’t responsible. However, any gateway worth its salt can mitigate the situation by detecting RTP loss and implementing SIP call recovery as discussed in last month’s post. In addition, as part of the process of failover recovery from far end RTP loss, any decent gateway will provide management notification of RTP loss via SNMP.
Good gateways will follow the ‘Robustness Principle’ of Jon Postel: “Be conservative in what you do, be liberal in what you accept from others.” Innovative gateways will not leave anything to chance – after all, Nostradamus never predicted anything good.
Click on the link if you want to know more about Aculab’s range of gateways or why not post a comment – or give us a call.
Ian Colville

If you recall the scenario, there is a gateway installed between an SS7 carrier network and an emergency services IP network – an ESInet – over which emergency calls are routed to public safety answering points (PSAPs). Calls entering the ESInet via the gateway are SIP/RTP/UDP and, as the NENA i3 specification quite rightly states, in no circumstances should an in-progress emergency call be taken down automatically, just because RTP streams fail.
Whatever effort you put into making the call handling equipment redundant and resilient, it is always best to assume that bad things can still happen. To misappropriate the principle of simplicity from Ockham’s razor, follow the rule of thumb that advises, “Make as few assumptions as possible.” In fact, make one assumption only – expect the worst (i.e., ‘the proverbial’ happens).
So, we can expect situations to arise in which RTP media between the gateway and the ESInet fails.
PSAP equipment must be able to distinguish between RTP failure and real silence by a caller. That capability must apply at all points on an ESInet where RTP media is encountered by a device – from the gateway right through to the PSAP. The gateway uses technology – some form of digital signal processing, using either hardware (DSPs) or software (HMP) – to encode the media, and that same functionality will be used to detect the presence of RTP streams and distinguish between packets of silence or ‘speech’.
So far, so good, but as suggested, in a prediction far more likely than a prophecy from a Nostradamus quatrain to come true, the worst will happen and an RTP stream will fail.
Using SIP OPTIONS here is not entirely adequate – yes, that’s a good method of monitoring the far end, but only in so far as it confirms the presence of a signalling capability at the User Agent. A 200OK response doesn’t confirm the presence of RTP; merely that the signalling link is functioning. So, for what are we catering?
It’s not a failure of the gateway with which we need to deal – it’s a failure from (or towards) the other end. It might be counterintuitive, but when the device at the far end fails, it doesn’t know it’s failed, because it can’t tell if the gateway has received any RTP. Furthermore, although the gateway can tell if it’s receiving RTP, it can’t tell if the other device is receiving its RTP. The point being, half the solution has to be implemented at each end in order to achieve a whole result. That is, similar signal processing functionality needs to be implemented at both ends.
If there’s been a failure in transmitting RTP from the remote end equipment, the gateway clearly isn’t responsible. However, any gateway worth its salt can mitigate the situation by detecting RTP loss and implementing SIP call recovery as discussed in last month’s post. In addition, as part of the process of failover recovery from far end RTP loss, any decent gateway will provide management notification of RTP loss via SNMP.
Good gateways will follow the ‘Robustness Principle’ of Jon Postel: “Be conservative in what you do, be liberal in what you accept from others.” Innovative gateways will not leave anything to chance – after all, Nostradamus never predicted anything good.
Click on the link if you want to know more about Aculab’s range of gateways or why not post a comment – or give us a call.
Ian Colville

 Technorati
Technorati Del.icio.us
Del.icio.us Slashdot
Slashdot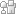 Digg
Digg twitter
twitter














Leave a comment