Key Takeaways:
• Simbian introduces the AI SOC LLM Leaderboard, the first benchmark to evaluate LLMs on end-to-end SOC alert investigation
• Benchmark tests models from Anthropic, OpenAI, Google, and DeepSeek in a lab environment with live tools
• Results show generalist LLMs that combine reasoning and coding outperform more narrowly specialized models
Simbian has announced the launch of what it describes as the industry’s first comprehensive benchmark to measure the performance of large language models (LLMs) in Security Operations Centers (SOCs). The AI SOC LLM Leaderboard evaluates how well different LLMs can autonomously complete end-to-end investigations of security alerts in realistic enterprise environments.
Unlike previous benchmarks that test general language reasoning or individual security tasks, Simbian’s new standard focuses exclusively on the most critical function of a SOC: alert investigation. The benchmark measures LLM performance from alert ingestion to final disposition and reporting.

“SOC analysts and vendors building tools for the SOC are rapidly embracing LLMs to scale their operations, increase accuracy, and reduce costs,” said Ambuj Kumar, CEO and Co-Founder of Simbian. “Our industry-first benchmark enables SOC teams and vendors to pick the best LLM for this purpose.”
Designed for Operational Relevance
Simbian’s benchmark evaluates LLMs across 100 diverse, full-kill-chain scenarios, using a testbed that simulates enterprise environments with live connections to SOC tools. Each LLM is challenged to:
- Interpret and contextualize alerts from different detection sources
- Decide which investigation steps to pursue
- Write code and scripts to pull relevant data
- Extract and reason over evidence
- Assign severity levels and produce clear incident reports
- Customize investigations based on organizational context
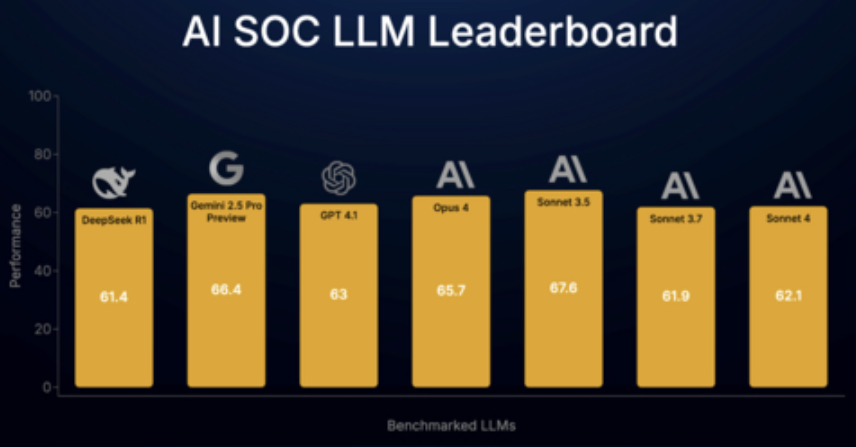
The benchmark relies on Simbian’s AI SOC Agent as the operational framework to break down investigations into discrete tasks that LLMs can execute. According to Simbian, all models tested—spanning Anthropic, OpenAI, Google, and DeepSeek—were able to complete between 61% and 67% of required investigation tasks when guided by this structured framework.
Findings on LLM Effectiveness
The benchmark surfaced several key insights:
- Generalist models like Sonnet 3.5 that balance reasoning and coding capabilities outperformed more specialized models such as Sonnet 4.0 or Opus 4, which focus heavily on either programming or logic alone
- SOC-specific training and model customization yielded better results than relying on any single off-the-shelf LLM
- The difference in performance between standard and so-called “thinking” LLMs was marginal for alert investigation tasks
The results also suggest that the best outcomes come from hybrid approaches—combining general-purpose LLMs with specialized tuning for SOC environments. Simbian plans to update the leaderboard periodically as new models emerge and existing ones evolve.
A Tool for Navigating Alert Fatigue
The benchmark arrives at a time when alert fatigue is intensifying across SOCs, exacerbated by the rise of AI-generated threats and increasing attack surface complexity. SOC teams are under pressure to respond faster and scale operations without proportionally increasing headcount.
Moreover, AI and hyperscale cloud vendors combined have enabled rogue hackers to amp up not only the quality of their attacks but the volume as well. AI is being used to help find blind spots in current IT systems.
Simbian positions its AI SOC Agent as a scalable solution to that challenge, capable of offloading routine investigations while maintaining or improving accuracy. The company reports that in a recent global competition, its agent outperformed more than 95% of over 100 human analysts in evidence-based alert investigations.
Strategic Implications
The AI SOC LLM Leaderboard gives cybersecurity teams, MSSPs, and vendors a practical tool for assessing which LLMs are best suited for real-world SOC use cases. By moving beyond synthetic evaluations and abstract NLP tests, the benchmark reflects what it actually takes to operationalize AI in cybersecurity environments.
Simbian’s broader mission is to solve security challenges through autonomous agents that behave like virtual employees—capable of executing tasks with speed, precision, and context awareness. The company is venture-backed and based in Mountain View, California part of Silicon Valley. No word on whether they will be renaming it to AI Valley, any time soon. 😉
Learn how AI Agents can supercharge your company’s profits and productivity at TMC’s AI Agent Event, Sept 29-30, 2025 in DC.

If you liked this post, you’ll love one of the the leading global business communications and technology events since 1999, the ITEXPO #TECHSUPERSHOW, Feb 10-12, 2026 Fort Lauderdale, Florida.
Don’t forget the collocated MSP Expo – just for managed service providers!
Aside from his role as CEO of TMC and chairman of ITEXPO #TECHSUPERSHOW Feb 10-12, 2026, Rich Tehrani is CEO of RT Advisors and a Registered Representative (investment banker) with and offering securities through Four Points Capital Partners LLC (Four Points) (Member FINRA/SIPC). He handles capital/debt raises as well as M&A. RT Advisors is not owned by Four Points.
The above is not an endorsement or recommendation to buy/sell any security or sector mentioned. No companies mentioned above are current or past clients of RT Advisors.
The views and opinions expressed above are those of the participants. While believed to be reliable, the information has not been independently verified for accuracy. Any broad, general statements made herein are provided for context only and should not be construed as exhaustive or universally applicable.
Portions of this article may have been developed with the assistance of artificial intelligence, which may have contributed to ideation, content generation, factual review, or editing