Key Takeaways:
• Gemini Diffusion uses denoising techniques instead of autoregressive token prediction
• Enables parallel generation of full text segments, improving speed and coherence
• Reduces hallucinations through iterative refinement
• Ideal for applications like coding, live translation, and interactive editing
• Matches or outperforms traditional LLMs in math and reasoning tasks
Google’s DeepMind team is challenging the prevailing architecture of large language models (LLMs) with a fundamentally different approach—one that could redefine how models are deployed and interacted with in real time. The new architecture, called Gemini Diffusion, forgoes the standard autoregressive method popularized by GPT-based systems in favor of a parallel, denoising-based strategy more closely aligned with how generative image models work.
A New Way to Generate Language
Traditional LLMs predict the next token in a sequence, generating one word at a time based on prior context. While this method has been refined and scaled successfully, it remains inherently linear and sequential. Gemini Diffusion, by contrast, begins with a noisy representation of text and progressively refines it through multiple steps, essentially “denoising” toward the desired output.
This approach allows Gemini Diffusion to generate large chunks of text simultaneously rather than one token at a time. It can also look forward and backward during generation—a non-causal technique that provides stronger global coherence across entire responses.
Performance Gains and Practical Implications
In early internal benchmarks, Gemini Diffusion achieved generation speeds of approximately 1,000 to 2,000 tokens per second—compared to about 270 tokens per second from Google’s previous Gemini 2.5 Flash model. This throughput leap could significantly reduce latency in enterprise applications that demand real-time interaction, such as chatbots, code assistants, and collaborative writing tools.
Beyond speed, the model’s refinement process introduces a built-in self-correction mechanism. Unlike autoregressive systems, which may compound errors as they progress, diffusion-based generation allows for multiple passes to polish content, reducing hallucinations and increasing factual consistency.
Trade-Offs and Challenges
Despite its advantages, the architecture has a few caveats. One is the delay in generating the first output token—since the process begins with a noisy input and takes several steps to refine it, the initial latency is higher than autoregressive models. This could be a drawback in use cases where time-to-first-token is critical.
There’s also the question of inference cost. Because the diffusion model requires more computation upfront to denoise the entire text block, it may not yet be as cost-effective in some production environments. However, Google suggests that its ability to dynamically adjust compute usage based on task complexity could make the approach more efficient over time.
Benchmark Results
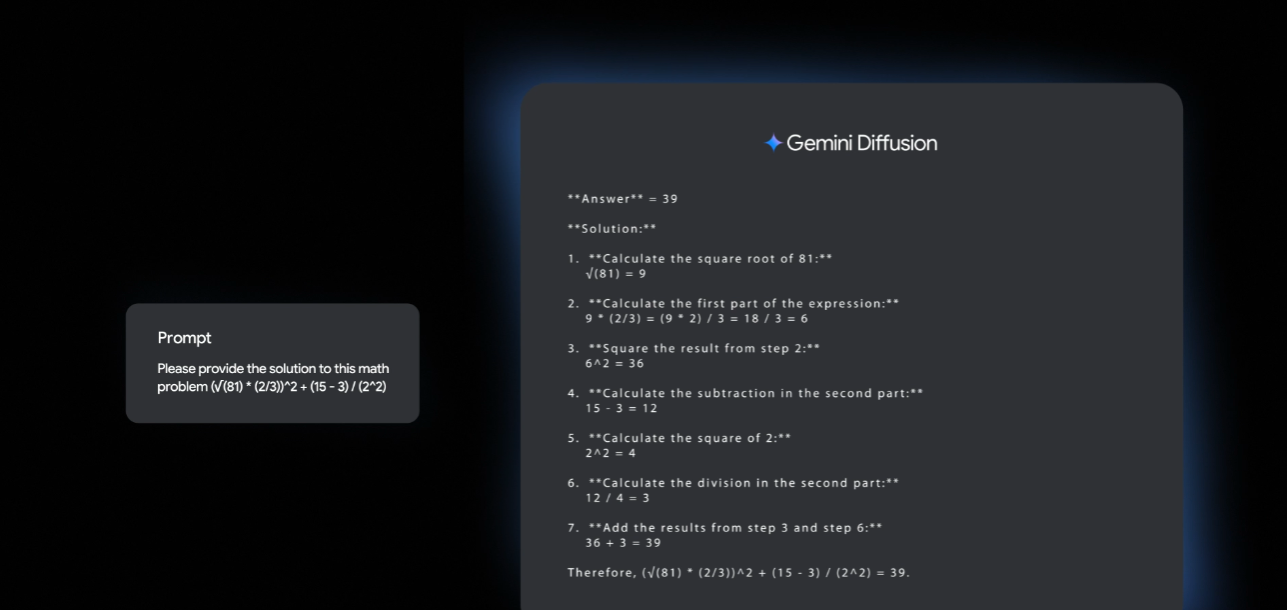
When tested on a range of reasoning, coding, and math tasks, Gemini Diffusion performed comparably to Flash-Lite models and in some cases even outperformed them—especially in code generation and mathematical problem solving. These are domains where precision and multi-step reasoning matter, suggesting that the iterative refinement process has distinct advantages for complex problem-solving.
The model also introduces capabilities not easily replicated with traditional LLMs, such as inline editing. Because it can reprocess and refine portions of text mid-stream, Gemini Diffusion is well-suited to dynamic content modification—offering practical use in grammar correction, document review, and live rewriting environments.
Future Implications
The architecture is still in development, but Google’s move into diffusion-based LLMs could have wide-reaching consequences. For enterprises seeking to embed language AI into workflows where speed, accuracy, and flexibility are critical, this model offers a new path forward.
Rather than simply scaling up existing architectures, diffusion-based LLMs represent a shift in how text is generated—allowing for faster responses, better global context, and easier corrections. These capabilities align closely with demands from sectors like healthcare, legal services, software development, and multilingual communication, where generative output must be precise, traceable, and responsive.
If Google continues to refine and deploy this model commercially, it may signal a broader shift in the LLM landscape—away from linear prediction engines and toward architectures that can reason, iterate, and adapt in more human-like ways.
Learn how AI Agents can supercharge your company’s profits and productivity at TMC’s AI Agent Event in Sept 29-30, 2025 in DC.
Rich Tehrani serves as CEO of TMC and chairman of ITEXPO #TECHSUPERSHOW Feb 10-12, 2026 and is CEO of RT Advisors and is a Registered Representative (investment banker) with and offering securities through Four Points Capital Partners LLC (Four Points) (Member FINRA/SIPC). He handles capital/debt raises as well as M&A. RT Advisors is not owned by Four Points.
The above is not an endorsement or recommendation to buy/sell any security or sector mentioned. No companies mentioned above are current or past clients of RT Advisors.
The views and opinions expressed above are those of the participants. While believed to be reliable, the information has not been independently verified for accuracy. Any broad, general statements made herein are provided for context only and should not be construed as exhaustive or universally applicable.
Portions of this article may have been developed with the assistance of artificial intelligence, which may have contributed to ideation, content generation, factual review, or editing.