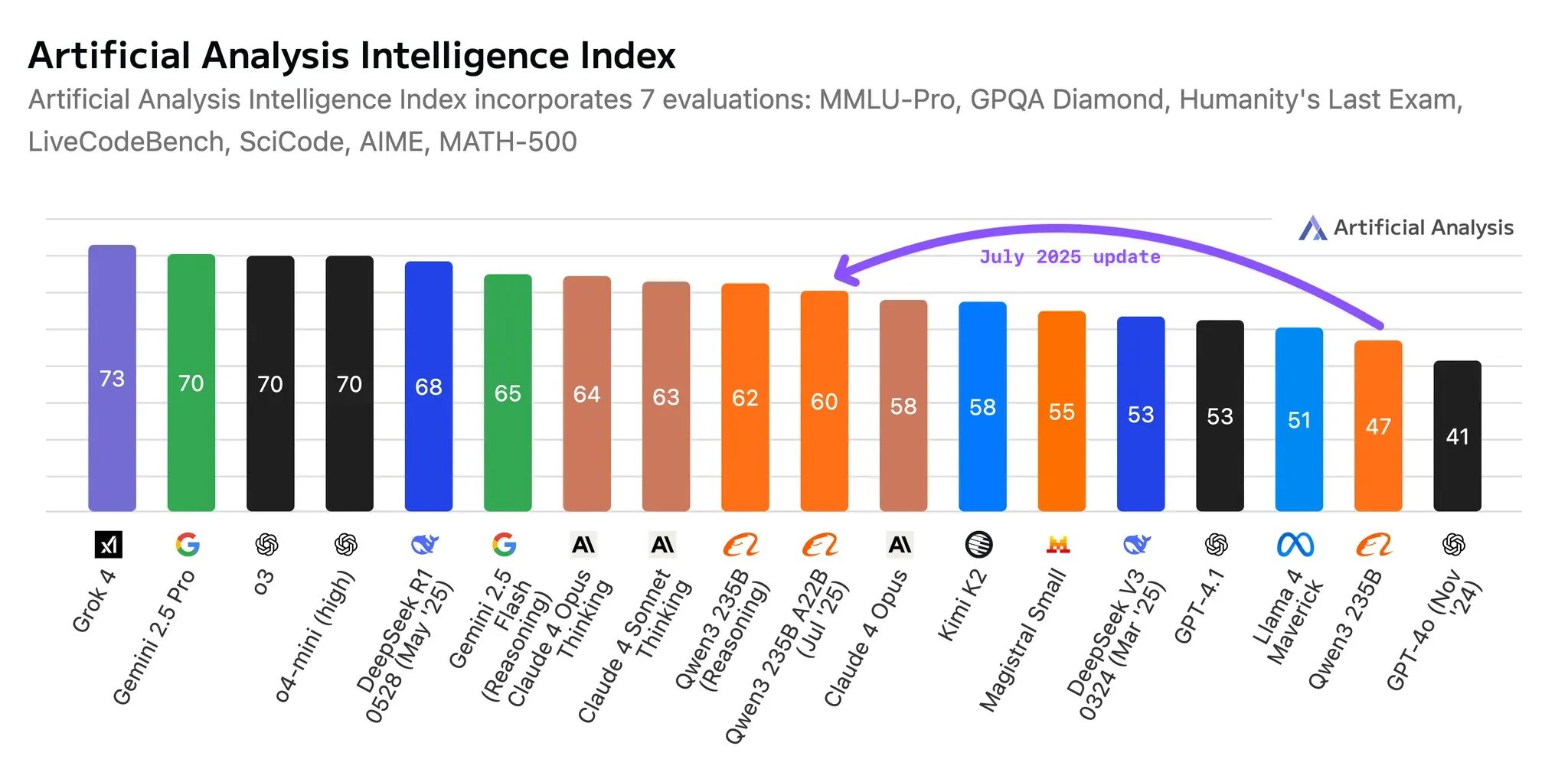
Photo courtesy of @ArtificialAnlys
Key Takeaways:
- Alibaba released Qwen3-235B-A22B-2507, an open-source language model that outperforms leading models like Kimi-2 and non-reasoning Claude Opus 4 on key benchmarks.
- A new FP8 quantized version reduces memory use by over 65%, doubles inference speed, and cuts power consumption by up to 50%, enabling low-cost deployment.
- The Qwen team has separated its instruct and reasoning models, abandoning hybrid design for optimized task-specific performance.
- Qwen3-2507 shows major improvements on MMLU-Pro, GPQA, SuperGPQA, and LiveCodeBench coding benchmarks.
- The model is released under an Apache 2.0 license and includes an agent framework for enterprise and developer use cases.
Alibaba has released an upgraded open-source large language model (LLM) under the Qwen3 banner, setting a new performance standard for the open-source ecosystem. The new version, officially labeled Qwen3-235B-A22B-2507-Instruct, surpasses its open competitors on key benchmarks while introducing major efficiency improvements that lower the barrier to enterprise and local deployment.
This launch reinforces Alibaba’s ambition to lead the open-source AI race, particularly for developers and enterprises seeking scalable, commercially usable models without the infrastructure demands of proprietary offerings.
Performance Against Leading Models
Qwen3-2507 marks a notable leap forward in open-source LLM performance. According to benchmark comparisons highlighted by Alibaba and third-party observers, the model outperforms Kimi-2 and the non-reasoning variant of Claude Opus 4 in several critical areas.
Among the most striking gains are:
- MMLU-Pro (a benchmark for general knowledge and reasoning): up from 75.2 to 83.0
- GPQA and SuperGPQA: improved by 15–20 points, reflecting better multi-hop question-answering accuracy
- LiveCodeBench (code generation): jumped from 32.9 to 51.8
- AIME25/ARC-AGI: doubled performance in several logic and reasoning tests
The improved scores demonstrate enhanced performance in both traditional LLM tasks (like factual QA and instruction following) and advanced use cases (like complex reasoning and code generation).
This places Qwen3-2507 firmly among the top tier of open models and shows that open development can rival or surpass some proprietary offerings when optimized effectively.

FP8 Version Reduces Hardware Footprint
One of the most important features of this release is the availability of a new FP8 quantized variant, which significantly reduces resource requirements.
This version requires only ~30 GB of memory, compared to ~88 GB for the standard float-16 model. This 65% reduction enables the model to run on systems with fewer high-end GPUs and lower power consumption—key requirements for mid-size enterprises and researchers.
According to Alibaba:
- Inference speed is nearly doubled compared to previous versions
- Power consumption is reduced by 30–50%
- The number of required A100 GPUs drops from eight to about four in many use cases
The result is that small teams and infrastructure-constrained organizations can now deploy a high-performing model without a multi-node GPU cluster. This democratizes LLM access for developers previously excluded from running models of this scale.
Separation of Instruct and Reasoning Models
Qwen3-2507 represents a strategic shift in design. Previous versions of Qwen used a hybrid toggle-based system where users could activate a “Thinking Mode” for chain-of-thought reasoning tasks. While novel, this architecture proved to be inconsistent for instruction-style tasks.
In response, Alibaba has now split the model series into dedicated instruct and reasoning variants. Qwen3-2507 is optimized for instruction following, with a separate reasoning model in development. This separation is designed to improve the performance and reliability of each version, and to simplify deployment and fine-tuning.
This new approach aligns with how many enterprises are customizing models for specific verticals: deploying separate agents or workflows for customer support, coding, summarization, and reasoning instead of relying on one-size-fits-all models.
Agent Framework and Licensing
Qwen3-2507 is available under the Apache 2.0 license, which permits unrestricted commercial use, customization, and redistribution. This makes it particularly appealing to enterprises that require auditability, data sovereignty, or on-premises deployment.
Alibaba is also releasing a lightweight agent development framework called Qwen-Agent, which helps developers build intelligent systems capable of tool use, plugin interaction, and task orchestration. This adds a layer of usability for developers building AI workflows that involve memory, file handling, and multistep reasoning.
In addition to the instruct model, the Qwen3 family includes a range of variants from 0.6B to 32B parameters, including Mixture of Experts (MoE) models, enabling scalability across deployment sizes.
Enterprise Use and Ecosystem Support
Qwen3-2507 integrates with modern open-source inference frameworks like vLLM and SGLang and supports fine-tuning methods such as LoRA and QLoRA. These features allow developers to adapt the model for their own domains using parameter-efficient training on smaller datasets.
Key enterprise features include:
- Full local deployment support with reduced hardware requirements
- Easy fine-tuning via LoRA/QLoRA
- Long-context window support for document tasks
- Strong multilingual support (including Chinese and English)
- Pre-tokenized and clean datasets for reproducibility and traceability
Combined with benchmark performance and licensing flexibility, these features make Qwen3-2507 an attractive alternative to commercial APIs for companies building LLM-based applications in regulated or resource-sensitive industries.
Market Response and Community Sentiment
The release has been well received by both the developer community and industry watchers. AI researcher and influencer “NIK” called Qwen3-2507 “stronger than Kimi K2” and “even better than Claude Opus 4” in non-reasoning tasks. Hugging Face’s Jeff Boudier commented on the model’s efficiency and high benchmark scores.
Developers have also praised the team’s decision to publish both the raw weights and the training methodology, supporting transparency and replicability—features that have become critical in open-source model evaluation.
The model’s availability on Hugging Face and GitHub allows immediate experimentation, while community discussions highlight the ease of loading and integrating the FP8 variant into existing inference pipelines.
What’s Ahead
According to Alibaba’s roadmap, more versions of Qwen3 are expected soon. These include:
- A dedicated reasoning model with advanced chain-of-thought capabilities
- Expanded multimodal support, building on progress from the Qwen2.5-Omni model
- New long-context models with up to 1 million token windows, potentially targeting document-heavy use cases in finance, law, and technical R&D
These developments suggest that Alibaba is not only focused on matching state-of-the-art performance, but on building a complete, scalable platform for AI model deployment that rivals commercial incumbents while remaining open and efficient.
Conclusion
Qwen3-2507 represents a meaningful step forward for open-source LLMs. With strong benchmark performance, reduced hardware requirements, and a permissive license, it makes high-quality AI more accessible to a wider range of users. Alibaba’s decision to separate its instruct and reasoning architectures reflects growing maturity in how LLMs are optimized and deployed.
As open models continue to close the gap with proprietary solutions, Qwen3-2507 offers a competitive, enterprise-friendly alternative that’s already making an impact in the AI ecosystem.
Learn how AI Agents can supercharge your company’s profits and productivity at TMC’s AI Agent Event in Sept 29-30, 2025 in DC.
Rich Tehrani serves as CEO of TMC and chairman of ITEXPO #TECHSUPERSHOW Feb 10-12, 2026 and is CEO of RT Advisors and is a Registered Representative (investment banker) with and offering securities through Four Points Capital Partners LLC (Four Points) (Member FINRA/SIPC). He handles capital/debt raises as well as M&A. RT Advisors is not owned by Four Points.
The above is not an endorsement or recommendation to buy/sell any security or sector mentioned. No companies mentioned above are current or past clients of RT Advisors.
The views and opinions expressed above are those of the participants. While believed to be reliable, the information has not been independently verified for accuracy. Any broad, general statements made herein are provided for context only and should not be construed as exhaustive or universally applicable.
Portions of this article may have been developed with the assistance of artificial intelligence, which may have contributed to ideation, content generation, factual review, or editing.